Academic Projects & Research
Research:
Robot Metabolism Project
Robot Metabolism Project
Biological organisms can metabolize: break down nutrients into basic building links and then use those building links to create new things. What if we could reproduce this kind of process in a robotic system?
This would allow many useful properties for engineering and manufacturing:
- Perfect reuse and recycling of modular elements from one object into another.
- Adaptation and robustness to fluctuations in resource availability.
- Self-repair.
- Autonomous design satisfying given functional requirements for the system.
Ultimately, we hope that such work can provide insights into the art and science of design, the process of creativity, and biological metabolism. We also aim for wide-ranging practical applications, in areas as diverse as disaster recovery, design engineering, and space exploration.
We are currently exploring these ideas in several areas. First, we have designed and constructed a robot testbed capable of reconfiguring simple truss structures, as shown in the concept image on the left. Second, we are working on devising genetic algorithms that are capable of performing reconfigurations of these such structures to fulfill given functional requirements. Finally, we hope to expand this work into larger fields of exploration: kinematic structures, automated design, and more.
Wyder, P.M.; Bakhda, R.; Zhao, M.; Booth, Q.A.; Modi, M.; Song, A.; Wu, J.; Patel, P.; Kasumi, R. Yi, D.; Garg, N.; Bhutoria,S.; Tong, E.; Mustel, O.; Kim, D.; Lipson, H. ”Robot Metabolism”, IEEE

Since May 2021, I have been collaborating with Philippe Martin Wyder on the Robot Metabolism research project in Hod Lipson’s Creative Machines Laboratory at Columbia University. My role primarily focuses on the hardware components of the project, where I contribute significantly to both the design and functional enhancements of the robotic systems we develop.
My efforts in the project have been pivotal in advancing our research goals. I led the construction of a substantial number of robot links, ensuring that we had the necessary resources for our experiments. I also redesigned these links to improve their functionality and streamlined the manufacturing process. By shifting the production to rely exclusively on FDM printing, I made the build process more efficient and accessible.
Additionally, I co-developed a physical simulation platform that has become essential for testing and refining our robot’s functionalities under controlled conditions before proceeding to live experiments. This platform aids in troubleshooting and optimizing the robot’s performance, ensuring robustness and reliability in real-world applications.
My deep involvement in 3D printing and my commitment to innovative robotics research have not only propelled the project forward but also enhanced the collaborative dynamics of our team. My technical skills and hands-on approach have been instrumental in navigating the complex challenges of developing cutting-edge robotic systems.
Robot Studio Project: Dancing Robot
this is a hands-on studio project that through the entire robot design process “from A to Z”, including kinematics, industrial design, manufacturing, electronics, simulation and programming. Jiahao builds this robot project in Columbia University Robot Studio Course and Professor is Hod Lipson.

The goal of this project is to design and construct an organic-looking legged robot. In this project, Jiahao made is a two-legged robot using three motors per leg, plus one optional motor for the body (seven motors total).
The robot uses serial bus revolute servomotors with a 240-degree range, a rechargeable battery, a Raspberry Pi computer and a motor controller.
Robot Gallery:






Project Video:
Evolutionary Algorithm
This project covered topics in evolutionary algorithms and their application to open-ended optimization and design. The field of evolutionary computation tries to address large-scale optimization and planning problems through stochastic population-based methods. It draws inspiration from evolutionary processes in nature and in engineering, and also serves as abstract models for these phenomena. Evolutionary processes are generally weak AI methods that require little information about the problem domain and hence can be applied across a wide variety of applications with relatively little upfront investment. They are especially useful for open-ended problem domains for which little prior formal knowledge exists and the number of parameters is undefined, such as for the general engineering design process. The project can provide insight to a variety of evolutionary computation paradigms, such as genetic algorithms, genetic programming, and evolutionary strategies, as well as governing dynamics of co-evolution, arms races and stable states.
Jiahao learned Evolutionary Algorithm at Columbia University Evolutionary Algorithm Course and professor is Hod Lipson
Application I: Traveling Salesman Man Problem
Three Algorithms used to find the shortest path, Random Search Algorithm, Hill Climber Algorithm, and Evolutionary Algorithm. In Evolutionary Algorithm, there are two different selection methods used, Stochastic Tournament selection method and Elitism selection method.
1.Random Search:
The principle of the random search algorithm in the Traveling Salesperson problem is to randomly generate the path and calculate the path. Each time after random path distance calculates, to compare the result with the shortest distance. If the result is shorter than the shortest distance, with the result replace the shortest distance as a new shortest distance.
About disadvantages by using a random search algorithm, this algorithm has no strategy, the random search may be the better solution for a smaller number of objects. it is the worst method to use when we have a huge number of objects, because more objects mean more possibility, in this case, when a salesperson has to travel 1000 cities, the possibility of the path will be very large. Another disadvantage is time request, it requests a huge amount of time to find better results than another method like the EA algorithm or Hill Climber algorithm. The advantage of using a random search algorithm is easier and faster than other algorithms.
Random search should be used in such a situation that has fewer objects and less possibility. If the TSP problem has a small number of cities, the random search algorithm will be a better choice.
2.Hill Climber:
For hill climber algorithm in TSP, the program not able to find best result, program by using hill climber algorithm only can find local best result, not global best results. It means hill climber is a local method, it decides what to do next by looking only at immediate consequences of its choices. However, hill climber algorithm will be useful in some other area/fields, such as circuit designing, vehicle routing and shop scheduling.
By using the Hill Climber Algorithm in the TSP problem, the salesperson will start with a random path, the path will start to find the smaller path by change the distance between cities, if the cost becomes smaller, the program set this shorter path as the current path and change the distance between cities based on this path until the program finds a path shorter than the current one.
For hill climber algorithm in TSP, the program not able to find best result, program by using hill climber algorithm only can find local best result, not global best results. It means hill climber is a local method, it decides what to do next by looking only at immediate consequences of its choices. However, hill climber algorithm will be useful in some other area/fields, such as circuit designing, vehicle routing and shop scheduling.
3.Evolutionary Algorithm:
The Evolutionary Algorithm is one of the efficient and global search methods. It can automatically acquire and accumulate knowledge about search space during the process running, and it can adaptively control the search process to find the best solution
The Evolutionary Algorithm process includes 5 steps, there are Initialize population, evaluation, selection, crossover, and mutation. Initialize Population provides the initial population which will input to EA process for evolution. Evaluation is to identify and calculate the fitness. The function of selection is able to select individuals from population-based on specific selection methods. The function of crossover (Recombination) is to use selected individuals as parents and combine the genetic information of two selected parents to generate a next-generation population. And the last step mutation, its function is that to maintain genetic diversity for a population.

Stochastic Tournament Selection Method
The principle of the Stochastic Tournament (ST) method is the method of competing between a pair or amount of population, the winner will be selected as one of the parents of the crossover section. In the TSP problem, after the evaluation section, individuals will compete with each other based on fitness. In the TSP problem, the fitness is reciprocal of distance, which means a path that has a short distance will be a winner.
Elitism Selection Method
Elitism selection in evolutionary algorithm means to select the top part of the population and crossover them. In the TSP problem, all populations (paths) will be sorted from small to big by the rate of fitness, elitism selection method will select from the individual which has a bigger rate than others, in TSP assignment, the percentage of selection is 50 %, which means the program will select 50% of the population from the biggest rate of fitness.
Crossover Method
The method of crossover is the signal point method. To identify the relationship between two parents in the proportion of children, set up different genes’ distribution methods for the comparison
Mutation
In this homework, the method of mutation is to randomly switch 100 points(cities) for an individual.
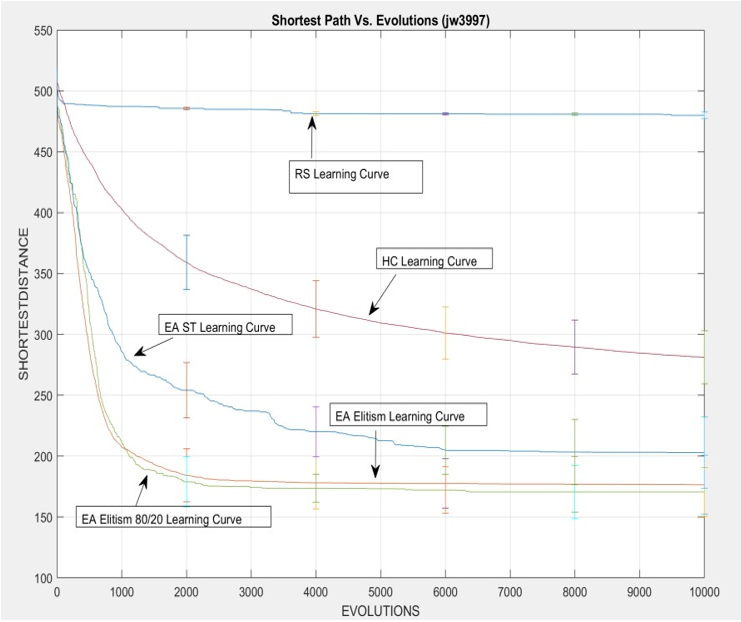
Overall Analysis
According to results from the above figures and results from data, traveling salesperson person problem by using random search, the shortest distance is 479.3722 and the longest path is 529.2552. The shortest distance by using the Hill Climber algorithm is 278.6888 and the longest path is 667.0091.
Random Search Shortest – Hill Climber Shortest = 200.6834 Hill Climber Longest – Random Search longest = 137.7529
Hill Climber algorithm provides a better result. Hill Climber can go 200.6834 lower and go 137.7529 higher than random search. Hill climbers have better performance than random searches in the TSP problem.
Hill Climber Shortest – EA with Stochastic Tournament Shortest = 98.8491 EA with Stochastic Tournament Longest – Hill Climber Longest =
To compared performance between hill climber algorithm and EA algorithm, EA can go 98.8491 lower and. based on results data EA has better performance than hill climber
EA with Stochastic Tournament Shortest – EA with Elitism Shortest = 18.0342 EA with Elitism Longest – EA with Stochastic Tournament Shortest = 45.1095
The difference between the above EAs is that using different selection methods, the results show the elitism selection method has better performance on both of shortest path and the longest path compared with the stochastic tournament method.
Base on the overall performance in the traveling salesperson problem, the EA algorithm is the best solution to solve the TSP problem. However, if the TSP problem has a small number of cities, Hill climber can be another faster and better way to solve this question. EA has many advantages for solving question that has complex space and a larger amount of possibility. If another problem has few possibilities or less complex, the hill climber and random search may be a better solution
Overall Performance: EA Elitism > EA ST > Hill Climber > Random Search
Application II: Symbolic Regression
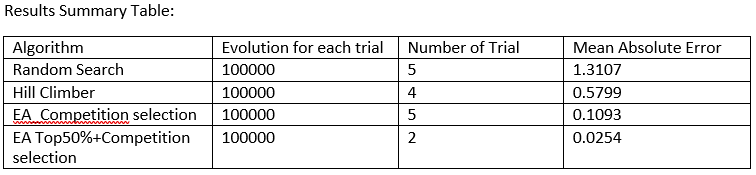
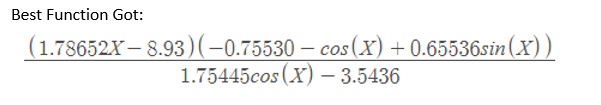
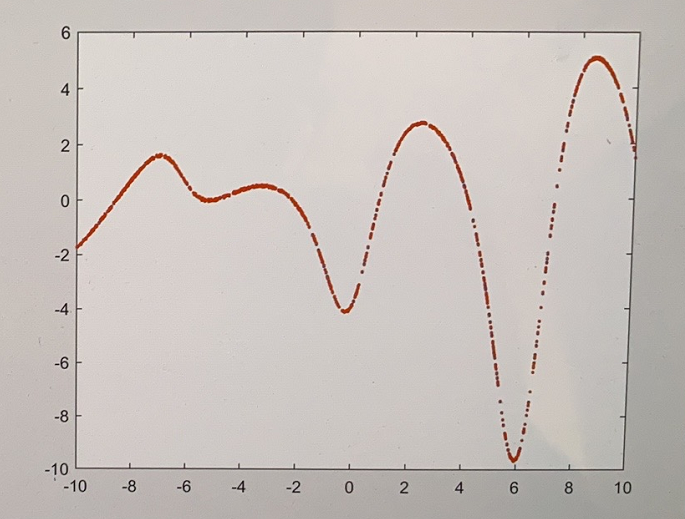
Representation used
Symbolic regression is one of the regression problems. Based on the given data, find the best model by searching the space of mathematical expressions. In this symbolic regression problem, the student needs to find the best function by using three different algorithms. The first is a random search algorithm, the second algorithm is hill climber and the last one is the evolutionary algorithm. In this problem, the heap binary structure used to build the binary tree. The binary tree can generate max 6 levels, and from level 0 to level 5. Level 0 has 1 node and it is the root nodes. Level 1 to 4 contains function nodes, root nodes and function nodes are same in this problem, such as addition and subtraction. The level 5 contains leaf nodes, the leaf node is either variable “x” or constants. However, node in level 1 to 4 still have possibility to select a constant or variables, if a node in level 1 to 4 to be selected as a constant or x, this node will be the leaf node also.
In heap binary tree, six different type of functions used in this problem, there are addition; subtraction; multiplication; division method; sin and cos. All the functions will be randomly selected to put into root and function nodes.
The recursion method is used in tree(formula) calculation, the idea of the recursion method is to search the binary tree from top to bottom, then combine the tree from bottom to top. The relation between nodes based on i and 2*i and 2*i+1. The program will identify the heap binary tree from top root level to leaf node which is whether constant or variable “x”. By using recursion, it is able to quickly calculate the result of this heap tree.
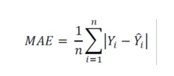
In this assignment, mean absolute error was used as the function of fitness calculation. Calculated y values will minus the correct answer of y, the absolute function will use on this result. All of the results of Y_Calculated – Y_correctanswer will summary together and then divided by 1000. The final results will be the mean of absolute error which is the fitness of this problem.
Random Search
For random search in symbolic regression, the method of this algorithm is that to randomly generate a formula of y=f(x). In random search, each formula has big differences between other formulas, which means the random search has no strategy or direction. The random search algorithm may provide better results at this time, but it not able to guarantee the same or better results will be provided by the next random formula of y=f(x). To get better results or 0 MAE, the total needed time will be very long because of its uncertainty.
In this problem, the root node called 1, first-level are under the root level, it has nodes are 2 and 3, second-level nodes from 4-7, the third level nodes from 8-15, the fourth level nodes included 16 to 31 and last level nodes from 31 to 63. All nodes will be saved into a list, this list will be representative of a heap binary tree. From the root level to the fourth level, nodes in root level and the first level has 100% of a possibility to receive a function, each node In level 2-4 has a 50% of a possibility to store a function
(+,-,x,/) or 50% of a possibility to be selection a constant or variable x. All functions(+-x/sincos) have the same possibility (17%) be selected. The fifth level contains all of the leaf nodes, each node has the same possibility as function nodes, it has a 50% possibility to select either a constant or select variable “x”.
Hill Climber
The hill climber algorithm is an improved algorithm based on the depth-first search algorithm. The principle of hill climber in the symbolic regression problem is that always pick the best formula and then keep modify this formula until having a better formula.

In this problem, the program will generate an initial formula (binary tree) about y=f(x). Then the program will run a modification function which remove and regenerate a subtree based on the current heap binary tree. to replace the subtree, the program will select a node from the root level to the fourth level as a start point. From start node, the program will remove this subtree and replace it with a new subtree. Subtree includes start point, and its 2*i and 2*i +1 point until the fifth level (leaf node). For example, if the start node is 8, this node and its sub-nodes 16 and 17 will have 30% of possibility to randomly select a new function or 70% of possibility does not change. For all related leaf nodes 32; 33; 34 and 35 are also have 70% of possibility to randomly select a constant or 30% of possibility to replaced with variable “x”.
After modification, the program will compare the current formula with the new formula by calculating mean absolute error. If the new formula provides a less mean absolute error, the program will replace the current formula with a new formula and then bring the new formula into the modification function for improvement.
Evolutionary Algorithm with Competition Selection Method
The principle of the evolutionary algorithm in symbolic regression is that to select, crossover, mutate a population and then combine all the next generations as the new population for the next evolution. In this problem, the population for each evolution is 60 and the population will evolve 100000 times.
Selection in this evolutionary algorithm by using competition selection. Before crossover and mutation, two parents (formulas) will be selected from selection function. The method of this selection function is that to random select two parents from current population and calculate the fitness (MAE) of two parents. Then compare the fitness of two parents and choice the one has less mean absolute error.
The method of crossover is to switch a subtree between two parents. The range of subtree between levels 2 to 3 and includes function nodes and leaf nodes. The program randomly selects a node from level 2 or level 3 as a first switch node. The first switch node and its sub-nodes will be the subtree for crossover. For example, if the first switch node is 4, this node and all of its sub-nodes are 4, 8, 9, 16, 17,18, 19, 32, 33, 34, 35, 36, 37, 38 and 39 will become the subtree for parent 1, parent 2 will provide the same subtree for crossover. The crossovers function is able to generate two children after crossover.
For the method of mutation, it is same with modification function in hill climber algorithm. Child will randomly remove one of subtree and replace with new subtree.
In this problem, 10 of 60 individuals in population will not going to evolve, those 10 individuals will directly put into new population, rest of 50 individuals going to evolutionary algorithm. The reason for keep 10 current population is that to keep the diversity of population and avoid the local maximum and reduction of diversity. This method will make sure population always on the right track.
In addition, after crossover and mutation and before a new population generates, the program will compare child and parent by calculating the mean absolute value of child and parent. If the mean absolute value of a child less than the mean absolute value of the parent, the program will select the child to be once of new population. On another hand, if the mean absolute value of parentless than the mean absolute value of the child, which means the child has less performance than the parent, the program will bring the parent in to new population instead of the child.
Evolutionary Algorithm with Top50% + Competition Selection Method
The difference between the two Evolutionary is the selection method. In this evolutionary algorithm, there is two selection method combined within this selection method, first one is top 50% selection method and next is competition selection. The selection function will first rank all of the individuals by calculating the mean absolute error value. The program then picks the top 50% of the population as the range of a selection for competition methods. competition method will then pick two parents for comparison from the range of top 50% of population. After competition, the parent who have less mean absolute error will be the individual of new population.
Overall result analysis
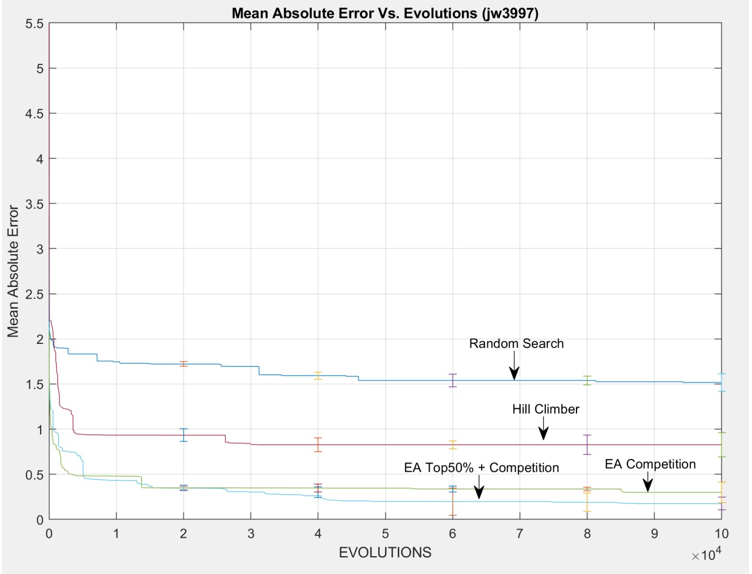
Random Search MAE – Hill Climber MAE = 0.7308.
According to results from figure 8. And above calculation. In the symbolic regression problem by using random search, the lowest mean absolute error is 1.3107. The lowest mean absolute error by using the hill climber algorithm is 0.5799. Compared to random search and hill climber, the hill climber has better performance than the random search in symbolic regression. The reason for this becaue of hill climber have direction of improvement. Even hill climber has the disadvantage of local maximun, hill climber allgorithm still able to provide the better result than random search algorithm.
Random Search MAE – EA with competition selection MAE = 1.1704 Hill Climber MAE – EA with competition selection MAE=0.4396
Based on results, an evolutionary algorithm with competition selection has a lower mean absolute error than both random search algorithm and hill climber algorithm. The smallest mean absolute error by using an evolutionary algorithm with competition selection is 0.1403. The mean absolute error of the evolutionary algorithm with the competition is 1.1704smaller than the random search and 0.4396 smaller than the hill Climber algorithm. Compared with random search, evolutionary algorithms have a strong pressure to find the right direction of improvement which means the evolutionary algorithm has a very strong strategy and is able to direct the way of evolution. Compared with the hill climber algorithm, the evolutionary algorithm can avoid the local maximum issue, it can make sure final results from evolution algorithm is the correct answer or very closed to correct answer.
EA with competition selection MAE – EA with Top 50% + competition selection MAE = 0.0312 Between two evolutionary algorithms, the difference is the selection method. one only uses the
competition method, and another EA uses two selection methods which are the top 50% selection and competition. In this program, the evolutionary algorithm has a bigger diversity, so it allows the program to added more selection pressure in order to increase the speed to get a better result and increase the accuracy of results. EA with top50% and competition has stranger selection pressure than EA with competition selection method. Based on overall performance in the symbolic regression problem, the evolution algorithm is the best solution to solve the symbolic regression problem.
Overall performance: EA top 50% + competition > EA competition > Hill Climber > Random Search.

Application III: Soft Robot Evolution
Let's see result first:
Speed of Fastest Robot in robot maximum diameter per cycle:
Known:
Length of cube edge: 0.025 m
dt=0.0001sec
Sum of dt: 0.02 sec
Longest traveled distance: 0.000545 m
Result:
Speed = 0.000545 /0.02=0.02725 m/sec
Diameter speed = 0.000545/0.025=0.0218 diameter/sec
Fastest Robot
Walking Robot:
Crawling Robot:
In this simulation, the team used both direct encoding and indirect encoding representation for constant k, b, and c. In the direct encoding method, the team assigned different [k, b, c] arrays to each spring ( 10 arrays for a tetrahedral ). In the Indirect encoding representation, the team used a spring dictionary contain 4 types of springs, which are hard support [ k = 25000, b = 0, c= 0], soft support [ k = 1000, b = 0, c = 0], and contract muscle [ k = 5000, b = 0.001, c = 0] and expand muscle [ k = 5000, b = 0.001, c = pi ]. Each spring is randomly assigned to different types of springs.
Furthermore, the team evolved the robot’s shape by using direct encoding.
To change the number of mass points in this project, the team mutates the initial length of each spring and mass distribution. The mass of each point is decreased or increased by a random number, and the initial rest length of the spring is changed by a random number( between 0.01 and 0.04 ). And, the robot has the possibility to add one more point. The spring array and position array are combined and pass into an evolution process.
The roulette wheel selection has been used as the selection function in this evolutionary algorithm. Before crossover and mutation, two parents(tetrahedral) will be selected from the selection function. The method of this selection function is that the fitness function assigns a probability of selection to each individual. This fitness level is used to associate a probability of selection with each individual. If an individual has bigger fitness than others, it will have a bigger possibility to be selected as the parents for the next generation. Compared with the roulette wheel selection, the team also makes another selection which is the top 50% selection. The method of this selection function is to randomly select the parent from the group whose fitness is in the top 50 % rank of fitness in this population. Compared results between two different selections applied, the roulette wheel selection is better than the top 50% selection method, so the wheel selection has been selected as a selection method for this evolutionary algorithm.
After two parents were selected, the team used mutation and crossover to generate children. In the direct representation, the team member randomly changes the k, b, and c values in the mutation process and exchanges a portion of the two parents in the crossover process. In indirect encoding, the team randomly chooses one type of string and switches to another type of spring. The morphology mutation process comes after the spring mutation. The robot generated by the indirect encoding usually performs better than the direct encoding representation. Thus, the team chose indirect encoding for 10000 evolutions. The team chose displacement as their fitness criteria, and they use parallel programming when evaluating the fitness for each population. The displacement was represented by the distance between the initial position and the final position. The diversity is calculated by counting the number of different populations in each evolution. In Phase B, the maximum speed of robot which after 10000 evolutions is 0.0002, but the team achieves 0.00055 maximum speed when the team changes morphology as well as locomotion.
As one of the important parts of evolutionary algorithms, diversity is always the key factor to affect the final evolution results. There are many different ways to maintain diversity. In this project, one of the methods the team used to maintain diversity is to select 6 different individuals in the current population and put them into the population of the next generation. Those 6 individuals will not go through the selection, crossover and mutation process. Evolutionary algorithms will produce the rest of 14 new individuals, those 14 new populations combined with 6 selected parents will become the next generation. There is another method teams use to keep good diversity, it is a selection process. Like the above discussion about the selection. The team uses roulette wheel selection, which means every one of 20 individuals in the population has the possibility
to be selected as one of the parents for next-generation produce. Using the above method, in this project, the diversity of the population has been maintained at a very good level.
Spring Evolution Per Second:
Below are the results of spring evolution per second: SEPS= 428 (spring per cube) * 12 (parallel) = 5136
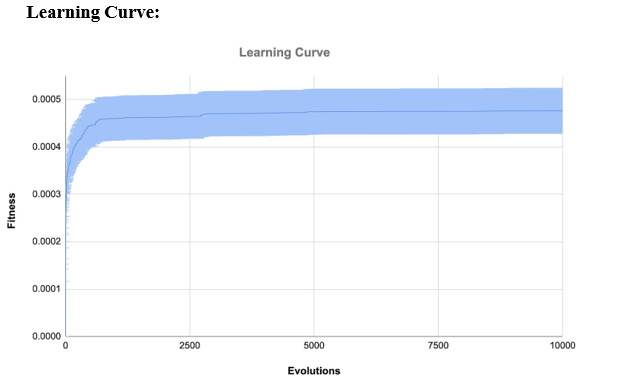
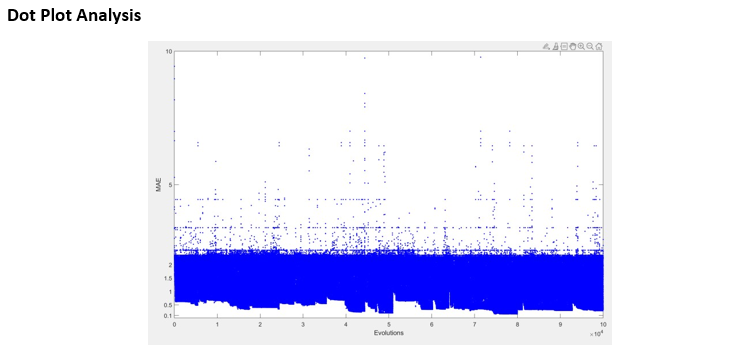
The team runs five trials for evolution and each trial has 10000 evolutions. The above figure shows the learning curve of the mean value of the five trails. In five trials, the fourth trial provides the best fitness and fastest robots, the fitness is 0.000545 and the third trial provides the smallest fitness which is 0.00037751. The highest fitness in the mean of five trials is 0.0004761. According to the diversity plot and dot plot below. This algorithm still maintains a good diversity and the dot plot shows the evolution of the population still in progress. It means if we increase the total evolution from 10000 to more, this algorithm is still able to evaluate robots and provide better and faster robots.
Each dot represents the fitness of an individual. Before 500 evolutions, most of the population stayed in the range between 0 to 0.0004. From 500 to 1000 generations, the population produced better individuals which shows many individuals stayed above 0.0004 but below 0.00047. When 5200 evolution, the population produces better individuals than previous, many individuals can provide fitness more than 0.0005.


The measurement of diversity is to count how many different individuals are in each evolution. In the beginning, the population has more than 19 different individuals. During the evolutionary, the number of different individuals of most of the evolutions stays in the range between 8 to 3. More diversity means more possibilities of evolution which will allow the population to keep evaluating more generations.
If you would like to see my code, please contact me or check my Github. you should have my permission before using my code.
Predict Amazon Stock Price By Using Machine Learning Algorithms
Abstract
In the stock market, stock investment’s biggest problem is that the information and data in the stock market are complex and excursive. Individual investors are not always able to receive useful and helpful information. Sometimes they even have to pay extra to get this kind of information. Until today, There are still fewer data science tools in the market which are able to provide comprehensive information to individual investors and use machine learning to help their investment decision. The individual investor often replies on some cost-free “Gossip” instead of scientific-technical analysis to decide the stock market’s next action. As a result, Individual investors often lose a lot of their investment for the above reasons.
Team plans to aid in such development by designing a machine model that can predict a daily close price for a company which could provide help and suggestions to individuals investors in their stock daily trade.
Project Objective & Goal
After the appearance of machine learning, more and more researchers realized that machine learning can be applied to stock information prediction. There are plenty of thoughts on using a company’s stock information such as daily open, daily close, daily high and daily volumes to predict the future stock price of this company. However, many cases approve that only using daily open, high, low, volumes to predict the stock close prices is not workable. In this project, the team develops a new idea to develop machine learning models to predict the daily close price for Amazon.
The goal of this project is to use the knowledge gained from data science courses to collect and analyze stock market data and develop a machine learning model that can predict the daily close price. From Yahoo financial API, the team is able to collect stock data and other technical indicators for stock data analysis and machine learning prediction model training.
The idea of this project is to input more variables such as using the company’s stock data which has more relationship with Amazon as one of the variables in machine learning model development. And the team also uses stock indicators such as VIX (volatility) index as variables and into machine learning models for a stock daily close price prediction. Furthermore, the team develops more than one machine learning model by using different methods to predict the amazon daily close price. The team compared each algorithm to find the best machine learning model that has highest accuracy in close price prediction. The team starts with basic machine learning algorithms such as linear regression and quadratic regression, and then develops advanced models like the deep neural network (DNN) and Long short-term memory (LSTM) model to predict the daily close price. As a result, the team expected to develop a machine learning model which was able to predict the amazon daily close price with high accuracy.
To achieve this project’s goals, the team decided to use Python as the primary program language. Python is widely used and is one of the favorite tools being a flexible and open-sourced language. Python has massive libraries that are used for data manipulation and analysis. Python also has a lot of useful tools to help the team develop the machine learning model and develop new features for data analysis.
Data Source
By comparing with multiple different data API sources, the team decided to use Yahoo finance API as data collection. Yahoo Finance is one of the reliable data sources for the stock market. It supports python language and is able to provide comprehensive stock market summaries, historical and real-time quotes. The team is able to get detailed information like date, open price, high price, low price, last price, close price, etc. And another advantage of using yahoo finance is that it has easy coding and responds faster than other stock API and supports python program language. It will help the team to make a comprehensive data analysis and develop a more accurate machine learning model for price prediction.
Data Selection
In this project, the team selected six different company stocks, and one stock market indicator index. All six companies either have similar business areas or have a close partnership or business competition with Amazon. The first company is Amazon (Stock symbol: AMZN), which is the company that the team expects to predict its daily close price. The second and third companies are Walmart (Stock symbol: WMT) and eBay (EBAY). Walmart is one of the largest physical sales companies in the world. And eBay is one of the large online sales companies, similar to Amazon. eBay, Walmart, and Amazon are competing between each other but also cooperating in the market. The three companies together represent the US retail industry. The fourth company is Alibaba (Stock symbol: BABA). For Alibaba, Just as most American consumers refer to Amazon as an e-commerce giant, Alibaba leads the Chinese e-commerce market. Apart from online sales, Alibaba and Amazon both have cloud businesses, which will make their relationship even closer in the stock market. The fifth and sixth companies stocks are Facebook and Google; the reason to choose Facebook and Google is because Facebook, Google, and Amazon are the leaders in US technology stocks, and therefore, each company’s behavior affects other stocks. The last variable team selected is one of the essential market indexes: the Volatility index (VIX). compared with normal stock, the VIX index has the opposite trend with market stock. VIX index starts to rise during times of financial stress and lessens as investors become complacent. The VIX index is one of the best options to use for the prediction of near-term market trends.
Linear Regression Model
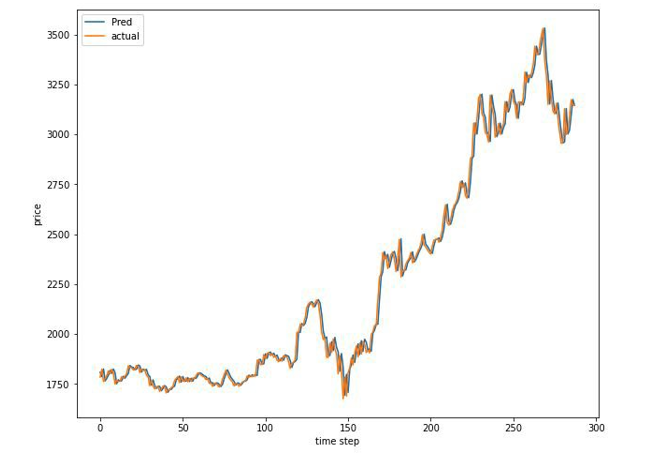
Polynomial Regression

Deep Neural Network

Long-Short Term Memory
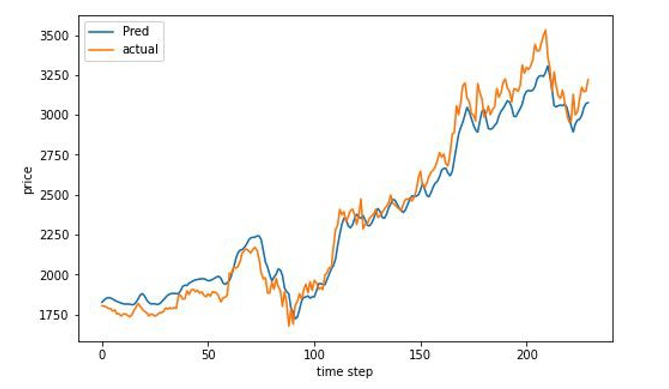
Method of Prediction Improvement Function

Since the machine learning model is able to provide an accurate stock movement. To improve the prediction results, the team developed a function that could combine the prediction with actual daily close price which to improve the prediction on next day’s daily close price. The principle of the adjustment function is based on predicted stock movement between the first and second day predicted close price, then added the movement into actual first day close price. The output of the function are adjusted second day predicted close price
Deep Neural Network
(Adjusted)
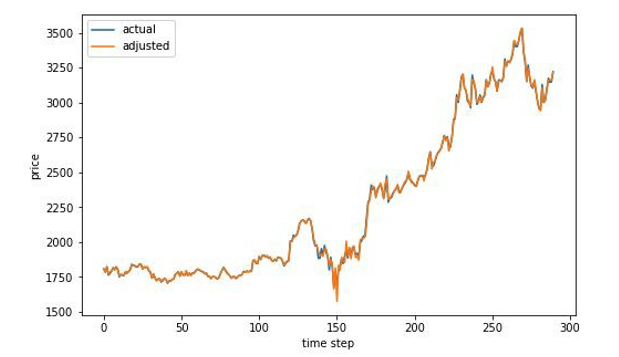
Long-Short Term Memory
(Adjusted)

Reference
- Linear Regression for Machine Learning, Brownlee https://machinelearningmastery.com/linear-regression-for-machine-learning/
- Basic classification: Classify images of clothing : TensorFlow Core https://www.tensorflow.org/tutorials/keras/classification
Ian Goodfellow, Yoshua Bengio, and Aaron Courville: Deep learning, Jeff Heaton ORCID: orcid.org/0000-0003-1496-40491
Understanding LSTM Networks, Cloah’s Blog, Aug 27, 2015
- Determining Market Direction With VIX, Summa, Aug 19, 2020 https://www.investopedia.com/articles/optioninvestor/03/091003.asp
Polynomial Regression, Agarwal, Oct 8, 2018
https://towardsdatascience.com/polynomial-regression-bbe8b9d97491